
Data is a critical element for any business, and although it has been essential in the past, the importance of data today surpasses anything we have seen before. Nearly every company requires data management to organize, protect, and maintain its data. Proper data management ensures data quality, security, and privacy. It also facilitates efficient access and retrieval and helps maintain compliance with legal and regulatory obligations. Navigating the world of data management can be challenging, especially with terms like "database," "data warehouse," "data lake," and "data hub." While these concepts may seem similar, they possess unique meanings and functions. Let's delve into the topic together to understand the differences between them and determine which one your organization needs.
The simplest is to distinguish databases from other concepts. Essentially, a database is a collection of data that is used to store and organize information. It serves as a central repository of all the data and allows multiple users to access and manipulate data simultaneously. They are typically accessed electronically and are used to support Online Transaction Processing (OLTP). They can be used to store various types of data across various industries and scenarios, including medical and financial records, online store inventory, sports statistics, student grades and scores, readings from IoT devices, and more. While databases are usually structured, they can also be unstructured or semi-structured. So, the main types of databases available are relational databases like Oracle, MySQL, and PostgreSQL, as well as non-relational databases such as MongoDB, Redis, Firebase, and others. For more detailed information on different types of databases, please refer to one of our previous articles, "The Best Database Options for Your 2023 Application."
In the current business landscape, though, having up-to-date information alone is no longer sufficient for achieving success. Nowadays, businesses of all sizes and industries are actively gathering and analyzing vast amounts of data from diverse sources to gain valuable insights that can improve decision-making. By utilizing business intelligence and analytics, such as sales, finance, customer, marketing, and supply chain reports, businesses can analyze data to optimize their processes and strategies. Forecasting, which includes sales, finance, workforce, demand, and economic projections, aids in planning inventory, production, budgeting, investment, recruitment, and retention.
An organization must identify the most suitable and secure storage solution to handle such large amounts of data effectively. Typically, organizations choose between data warehouses, data lakes, or a hybrid of both. While these storage options support Online Analytical Processing (OLAP), they differ in their data types and management approaches. Generally, data warehouses store structured data that has been organized and processed for reporting and analysis. In contrast, data lakes house unstructured or semi-structured data in its raw form, providing opportunities for exploration and analysis as needed.
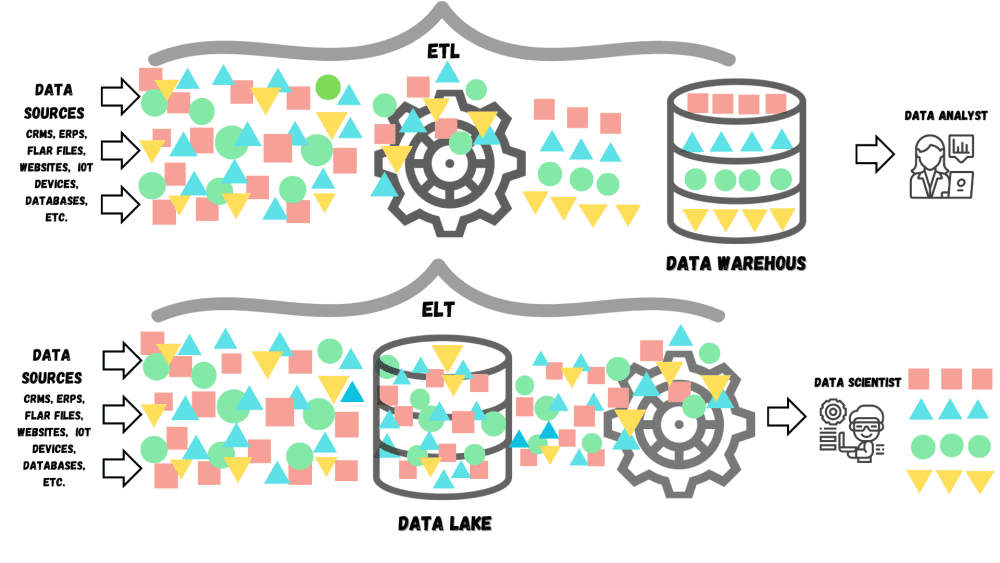
Let's take a closer look at the data warehouse. It's a centralized repository that stores vast amounts of structured and organized data collected from different sources. It contains data available in other databases but organized specifically for the questions the organization may want to ask. In simpler terms, a data warehouse is a massive relational database designed for analytics. Its primary function is to support business intelligence activities, such as data analysis and reporting. They typically have a predefined and fixed relational schema. Therefore, they work well with structured data. Companies choose data warehouses when they require immediate access to data from operational systems for analysis. With the capability to collect large-scale data, data warehouses play a critical role in helping companies achieve a comprehensive understanding of their operations. Allied Market Research has predicted that the global data warehousing market is projected to reach $51.18 billion by 2028.
A data warehouse uses the ETL (Extract, Transform, Load) approach to collect data from various sources on a regular schedule (for example, hourly or daily), transform the data into a format suitable for analysis, and load it into the data warehouse. The ETL approach is often regarded as slow due to its method of transmitting data in batches. Once the data is in the warehouse, it can be connected with business intelligence tools. These tools allow exploring the data, looking for insights, and generating reports for business stakeholders. They are accessible to a broad range of individuals and are generally used by business analysts rather than data scientists.
Data warehouses can be complex models with multiple layers structured into different tiers to handle various data storage and retrieval aspects. The bottom tier of a data warehouse usually consists of a relational database system, where data is stored in a structured and organized manner. The middle tier typically includes an OLAP (Online Analytical Processing) server offering data analysis and reporting tools. This tier acts as a mediator between the database and the end-user, simplifying and streamlining the process of querying and retrieving data. The top tier is commonly the frontend tier, which connects to APIs and other tools to enable users to access and interact with the data stored in the data warehouse. This tier is often responsible for collecting and presenting data in a user-friendly format, including features like dashboards, visualizations, and other tools to assist users in comprehending the data.
The following are some of the key characteristics of data warehouses:
- Subject-Oriented: A data warehouse is primarily designed to store and analyze business data across different domains. To make sense of the data, it is organized around a specific subject known as a data model. For instance, a data model could revolve around a sales region or the total sales of a particular item. This structured approach enables users to quickly identify and analyze data relevant to their specific needs.
- Integrated: Data warehouses are built by integrating data from multiple sources, such as transactional systems, operational systems, and external data sources. The data is transformed and consolidated to ensure consistency and accuracy.
- Time-Variant: Data warehouses store historical data and allow users to analyze trends and patterns over time. It is achieved by storing data linked to specific time periods.
- Non-volatile: Once data is loaded into a data warehouse, it is not changed or deleted. It ensures data consistency and makes it easier to track changes over time.
- Large-Scale: Data warehouses are designed to handle large volumes of data. They can support complex queries that involve millions of rows of data.
- Optimized for Querying and Analysis: Data warehouses are optimized for fast querying and analysis. They use techniques such as indexing, partitioning, and materialized views to improve performance.
- Schema-on-write: Data warehouses use a schema-on-write approach, which means that data is structured and transformed as it is loaded into the data warehouse. It allows for faster query performance and easier data analysis, as the data is already organized and optimized for querying. However, it also requires more up-front planning and design work to create the schema and transform the data, and it may not be as flexible or adaptable to changing data needs as a data lake.
- User-Friendly: Data warehouses are designed to be user-friendly and accessible to non-technical users. They provide tools for querying and analysis, such as OLAP cubes, dashboards, and reports.
Data warehouses can be on-premises and cloud types based on their technical design, storage, and processing capabilities. On-premises data warehouses are the classic variant that requires dedicated hardware and software for unified data storage. In contrast, cloud warehouses are hosted in the cloud and delivered as a managed service by a cloud provider. Popular cloud data warehousing solutions include:
- Amazon Redshift - a cloud-based fully managed data warehouse PaaS provided by AWS designed to handle large amounts of data and perform complex queries with high performance and scalability, making it a popular choice for businesses of all sizes seeking to store and analyze their data.
- Google BigQuery - a cloud-based, fully managed data warehouse PaaS supported by Google that enables users to analyze large and complex datasets using SQL queries.
- Microsoft Azure Synapse (previously known as Azure SQL Data Warehouse) - a cloud-based PaaS offering on Azure platform that combines big data and data warehousing into a single service.
- Oracle Autonomous Data Warehouse - a cloud-based fully managed database, categorized as a PaaS offering, tuned and optimized for data warehouse workloads with the market-leading performance of Oracle Database.
- IBM Db2 Warehouse - is a cloud-based client-managed analytics data warehouse categorized as a PaaS offering and built on IBM's platform that features in-memory data processing and in-database analytics.
- Cloudera Data Warehouse - a fully managed cloud SaaS offering built on Cloudera's data management and analytics platform that provides an automated and scalable data warehousing and analytics solution.
- Snowflake - a cloud-based data warehousing SaaS provided by Snowflake Computing that is available as a plug-and-play application and can be hosted on multiple cloud platforms like Azure, AWS, or Google Cloud.
- Panoply - a fully managed cloud-based data management SaaS provided by Panoply.io for data warehousing and analytics.
Now, let's approach data lakes. Data lake architecture was developed as a response to the constraints of data warehouse architecture, offering enhanced capabilities for managing unstructured and differently structured data. A data lake can also be defined as a unified repository, but for all structured and unstructured enterprise data. In addition to traditional relational data, a data lake can store semi-structured data, such as JSON documents and XML files, as well as unstructured data, such as PDFs, images, audio files, binary data, and more. It's essentially a massive pool of raw data that hasn't been organized or processed yet. According to a Grand View Research report, the global data lake market size was valued at USD 7.6 billion in 2019 and is expected to grow at a compound annual growth rate (CAGR) of 20.6% from 2020 to 2027.
Data lakes use the ELT (extract load transform) process. ELT provides greater scalability and flexibility since it enables organizations to store large amounts of unstructured data and avoid the need to transform data before it is loaded into the data lake. Data lakes accept raw data from various sources with minimal quality assurance and require consumers to process and improve the data's quality and value manually. This raw data can then be processed and transformed as needed for specific use cases rather than upfront, allowing for more customized data analysis and insights. Data can be analyzed using a range of OLAP systems and can be visualized using various BI tools. Despite needing significant storage capacity, data lakes are ideal for AI/ML-driven applications and data scientists as they facilitate the exploration of new and innovative ways to use the data. Data scientists use a combination of various tools, machine learning principles, and algorithms to find patterns from the raw data. Additionally, ELT allows organizations to leverage more powerful and flexible data processing tools, such as Apache Spark and Hadoop, which can be used to analyze and transform data directly in the data lake.
While data lakes may have some level of organization or partitioning, they do not typically have defined "levels" as in a traditional data warehouse or hierarchical data storage system. Data can be accessed and processed in various ways, including batch processing, real-time processing, and machine learning algorithms. It is also important to note that data lakes may have latency in data processing, depending on the specific tools and processes used to extract insights from the data. Some data may be stored "at rest" in the data lake, while other data may be processed in real-time.
The main characteristics of a data lake are as follows:
- Scalable: Data lakes are designed to handle large volumes of data. They can store data in the order of petabytes and beyond.
- Flexible: Data lakes can store data of any type, including structured, semi-structured, and unstructured data. This flexibility allows organizations to store all data types in a single location.
- Cost-Effective: Data lakes are cost-effective because they use commodity hardware and open-source software. It makes it easy for organizations to scale their data storage needs without incurring high costs.
- Schema-on-Read: Data lakes use a schema-on-read approach, meaning that data is stored in its raw form until needed. This approach allows organizations to store data in its native format, which makes it easier to process and analyze.
- Agile: Data lakes are designed to be agile, so they can quickly adapt to changing business needs. This agility allows organizations to respond quickly to new business opportunities.
Like data warehouses, data lakes can be implemented as on-premises or cloud-based solutions. Popular data lake solutions include:
- Amazon S3 - a cloud-based and fully managed object storage service in the form of an IaaS offering provided by AWS that provides secure, durable, and scalable storage for various data types and use cases.
- Microsoft Azure Data Lake Storage Gen2 - a cloud-based, fully managed data storage service in the form of a PaaS offering provided by Microsoft Azure. It combines the scalability and cost-effectiveness of object storage with the performance and reliability of a file system. The name "Gen2" refers to the fact that this service is an evolution of the original Azure Data Lake Storage, adding new features such as hierarchical namespace and integrated Azure Blob Storage.
- Google Cloud Storage - a cloud-based object storage service in the form of an IaaS offering provided by Google Cloud Platform. It provides a fully managed, highly available, and durable object storage service that can be used to store and access any type of data from anywhere in the world.
- IBM Cloud Object Storage - a cloud-based and fully managed object storage service provided by IBM Cloud as an IaaS offering. It allows users to store and retrieve data from anywhere on the web.
- Cloudera Data Lake - a cloud-based and fully managed Paas offering provided by Cloudera for storing, managing, and analyzing large amounts of data in various formats, including structured, semi-structured, and unstructured data. It offers a hybrid solution that can be deployed on-premises, on cloud infrastructure, or in a hybrid environment.
- Atlas Data Lake - is a cloud-based and fully managed data lake PaaS solution offered by MongoDB. Built on top of MongoDB Atlas, a cloud-hosted, fully-managed database service that provides a variety of features such as automatic scaling, high availability, and security, it allows users to store and query data across a variety of sources, including MongoDB databases, Apache Hadoop file systems, and Amazon S3 buckets.
- Snowflake data lake - a cloud-based fully-managed SaaS offering of the Snowflake cloud data warehousing and analytics platform that enables customers to store and query both structured and semi-structured data.
Now that we understand the difference between data warehouses, which are optimized to provide fast and accurate responses to predefined queries, and data lakes, which are designed to answer previously unknown questions, you might be wondering, what is a data hub then? A data hub is not a repository, it is more like an architectural approach that combines data integration, storage, orchestration tools, management, governance, and delivery, acting as a central platform that consolidates data from multiple sources in real time, providing a unified view of the organization's data. Unlike data warehouses and data lakes, a data hub is not simply a repository for storing data. It enables the bidirectional flow and exchange of structured, semi-structured, and unstructured data between sources and endpoints. In other words, a data hub serves as a central platform for integrating, managing, and delivering data. Data warehouses and data lakes can both serve as sources of data and endpoints for a data hub. However, unlike data warehouses and data lakes, data hubs do not store transaction information and are typically smaller in size.

A data hub allows for more uniformity in enterprise data and enables diverse users, whether an application, a data scientist, or a business user, to access information rapidly and accurately. It also allows for managing data for various tasks, providing centralized governance and data flow control capabilities, thereby ensuring that organizations are more comfortable with the legalities because they can tell you who in their company has access to what data and where that data is stored. This solution can be an excellent option for organizations that require real-time integration and management of data from multiple sources, ensuring that the data is accurate, up-to-date, and easily accessible for analysis and decision-making.
The architecture of a data hub consists of multiple layers that include data sources, data integration, harmonization, processing, orchestration, delivery, and data access layers. Data sources feed into the data integration layer, which processes and transforms the data into a consistent format for harmonization. The harmonization layer unifies and standardizes the data, which is then processed and orchestrated in the processing and orchestration layers. The delivery layer then distributes the harmonized data to endpoint systems, and the data access layer provides controlled access to the data by different users. Additionally, a data hub may have governance, security, and metadata management layers to ensure data quality, security, and compliance.
Here are some common characteristics of a data hub:
- Data integration: A data hub enables data integration by providing tools and services that can connect to various data sources, transform data, and load it into the hub.
- Data governance: A data hub enforces data governance policies that ensure data quality, security, and compliance with regulatory requirements.
- Data sharing: A data hub enables data sharing among users and applications, which promotes collaboration and improves decision-making.
- Scalability: A data hub is designed to scale easily to accommodate large volumes of data and high data processing demands.
- Flexibility: A data hub supports various data formats and types, including structured, semi-structured, and unstructured data.
- Analytics and reporting: A data hub provides tools for data analysis, reporting, and visualization, which enables users to gain insights from their data.
Data hubs can also be implemented both on-premises and in the cloud. On-premises data hubs are installed and maintained within an organization's own infrastructure. In contrast, cloud-based data hubs are hosted by a cloud provider and delivered as a managed service over the internet. There are several popular data hub solutions available today, including:
- Cloudera Enterprise Data Hub - a platform provided by Cloudera that enables organizations to manage and analyze large volumes of data using Hadoop, Spark, and other open-source big data technologies from various sources in a unified manner. It can be deployed either on-premises or in the cloud.
- MarkLogic Data Hub - is a software platform that allows organizations to integrate, store, manage, and analyze large volumes of structured and unstructured data from various sources. It uses a multi-model database approach, which allows for storing data in different formats such as JSON, XML, RDF, and Text. It can be deployed either on-premises or in the cloud.
- AWS Data Hub - a cloud-based data management platform provided by AWS that enables organizations to build a centralized repository for storing, managing, and sharing data across their entire organization.
- Informatica Data Hub - data integration and management platform that provides a central location for managing and governing data across various systems and applications. It can be deployed on-premises, in the cloud, or in a hybrid environment.
- SAP Data Hub - a cloud-based data sharing, pipelining, and orchestration solution accelerating and expanding data flow in various data environments.
- CKAN - an open-source data portal platform for managing, sharing, and publishing data. It provides a user-friendly interface for managing and publishing data sets, supports various formats, and includes data management and quality control tools. It can be deployed either on-premises or in the cloud.
In summary, the importance of effective data management for businesses cannot be overstated. It is crucial for companies to derive valuable insights from their data, make informed decisions, and gain a competitive edge. To achieve this, organizations can leverage data warehouses, data lakes, and data hubs, which all serve the common goal of efficient data management, but with unique features and capabilities. Data and analytics leaders should not choose one over the other but rather consider a combination of a data hub with either a data warehouse or a data lake to meet both current and future needs. To modernize data management infrastructure, the goal should be to create a dynamic system that can adapt to changes over time by facilitating new connections and supporting a wide range of use cases. By selecting the most suitable data management solution, companies can extract valuable insights from their data, make informed decisions, and gain a competitive edge in today's data-driven business landscape.
Reading time 13 min 38 sec