This is where most companies are hitting walls. An agent that shines in a controlled environment often struggles once exposed to real data, messy APIs, unpredictable users, and dynamic business processes.
In this article, we’ll explore the top reasons why AI agents fail in production and, more importantly, what companies can do to overcome these challenges.
The Growing Gap Between Demos and Production Reality
As organizations move agents from proof-of-concept to live environments, performance frequently drops sharply. Context windows fill up. Edge cases multiply. APIs fail. Costs escalate. What looked impressive in isolation becomes unreliable at scale.
It doesn't mean AI agents don't work. Many organizations are already generating real business value from them. The core issue usually isn’t the underlying models - it’s the engineering required to build robust, production-grade systems around them.
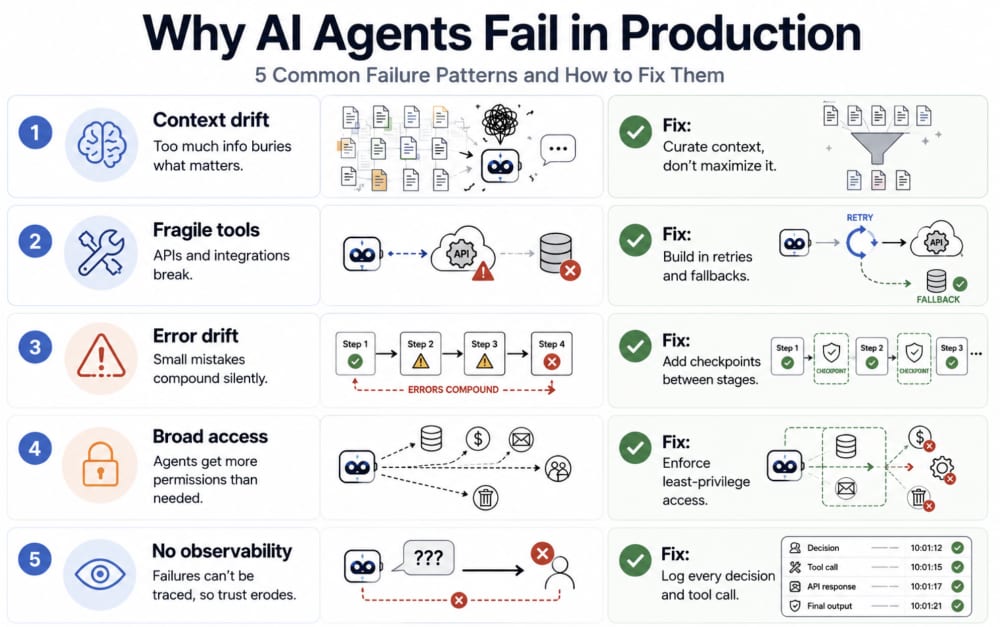
Here are the main reasons why AI Agents fail in production and how to fix them:
Reason 1: Poor Context Management and Retrieval Quality
When organizations deploy AI agents, they often connect them to everything: internal documentation, knowledge bases, CRM systems, support tickets, product specifications, meeting notes, and countless other sources, thinking that more information will improve their performance.
In practice, the opposite often happens. As agents move through multi-step workflows, they accumulate information, instructions, previous actions, retrieved documents, and conversation history. Over time, the signal-to-noise ratio gets worse. Important details become harder to identify. The model spends more effort processing information than reasoning about the task itself.
Retrieval systems introduce another challenge. They often prioritize relevance rather than quality. A document may be semantically related to the task at hand, but that doesn't mean it's accurate, complete, or the best source of information for making a decision.
As a result, agents can struggle for two reasons: they may fail to identify the most important information within a growing body of context, or they may rely on information that shouldn't have influenced the outcome in the first place.
Larger context windows (multiple frontier models now operate in the 200K to 1M+ token range) have helped, but they haven't solved the underlying problem. The challenge isn't simply storing more information. It's maintaining focus on the information that matters.
As workflows become longer and more complex, performance can gradually degrade. The agent continues responding confidently, but accuracy starts to decline. The system doesn't stop working - it simply becomes less reliable.
How to Fix It
The solution isn't a bigger context window - it is treating context as a managed resource.
Instead of giving a single agent access to everything, break workflows into smaller tasks.
Use retrieval systems that provide only the information needed for the current step. Prioritize trusted and high-quality sources. Summarize or compress stale context instead of allowing it to accumulate indefinitely. Use specialized agents that focus on specific responsibilities, rather than forcing a single agent to carry the entire workflow history.
The goal isn't to maximize context. The goal is to maximize relevance.
Reason 2: Fragile Tool Integrations
One of the biggest misconceptions about AI agents is that their performance is primarily determined by the model. In reality, most production agents spend a significant portion of their time interacting with external systems. They query databases. Update CRM records. Call APIs. Send messages. Trigger workflows. Access internal tools. And every one of those interactions introduces a potential point of failure.
An agent may correctly identify the next action to take and still fail to complete the task because a dependency becomes unavailable, a response format changes, a permission expires, or an external service returns an unexpected result.
The challenge is that production environments are inherently unreliable. Integrations that worked perfectly yesterday can suddenly stop working without warning. APIs fail. Request limits change. Authentication tokens expire. Data schemas evolve. Third-party services experience outages.
As organizations connect agents to more systems, the problem becomes harder to manage. Each new integration creates another dependency, another failure mode, and another source of operational complexity. This is one of the reasons many agent pilots perform well initially but struggle to scale. Intelligence may work. The orchestration around it becomes increasingly fragile.
How to Fix It
The solution is to stop treating external connections as reliable operations as they can fail at any time.
If a system doesn't respond, the agent should be able to retry. If a tool is unavailable, it should have an alternative path forward. If information looks incomplete or inconsistent, it should recognize that before acting on it. Most importantly, agents should be able to fail gracefully. Instead of generating incorrect outputs or abandoning a workflow entirely, they should communicate what went wrong, continue where possible, and surface issues that require human attention.
Integrations should be monitored continuously, and failures should be detected quickly before they affect customers or business operations. Opt for event-driven architecture, where systems push updates when something changes instead of waiting for the agent to request them. Just as importantly, teams should treat integrations as long-term engineering assets rather than one-time setup tasks.
Reliability rarely comes from the model itself. More often, it comes from the engineering discipline used to build the systems around it.
Reason 3: Compounding Errors in Multi-Step Workflows
One of the most underestimated problems in AI agent systems is that errors rarely stay isolated. In single-step tasks, a mistake is contained. In multi-step workflows, it propagates. The core issue is not that agents make mistakes. It is that mistakes accumulate without being corrected.
Most production agent systems are not one decision. They are a chain of decisions: retrieval, planning, tool selection, execution, and validation. Each step may look correct in isolation. But small errors at each stage accumulate as the workflow progresses.
A retrieval step may surface a slightly outdated or irrelevant context. The planning step then decomposes the task based on that context. The tool execution step follows the plan correctly, but the plan itself is already misaligned with the original intent.
Individually, nothing fails in an obvious way. Collectively, the system drifts. This is what makes these failures difficult to detect. There is rarely a single point where the system clearly breaks. Each component behaves as expected, yet the final outcome is incorrect.
The longer the workflow, the more pronounced this effect becomes. Even high per-step reliability degrades quickly when multiplied across multiple stages. The system can be technically “correct” at every step and still fail at the outcome level.
How to Fix It
The solution is not to assume higher accuracy at each step, but to reduce how far errors can propagate.
It means introducing checkpoints between critical stages of a workflow. Validating intermediate outputs before they are passed downstream. Limiting how much autonomy is given to any single step in a multi-stage process.
In practice, this often means separating concerns: retrieval, planning, and execution should not operate as a single continuous chain without interruption. Just as importantly, any action that is difficult or impossible to reverse - sending messages, updating records, executing financial operations - should require explicit confirmation before execution.
The goal is not to eliminate errors. It is to prevent small errors from becoming system-wide failures.
Reason 4: Permission Boundary Violations
One of the most common failure patterns in AI agents in production is not related to intelligence. It’s related to access. Agents that perform reliably in production tend to share a simple property: they operate within a clearly defined boundary. They are given a specific domain, a limited set of tools, and explicit constraints on what they can and cannot do.
The opposite approach, giving agents broad access “just in case” , is where problems begin.
In many systems, permissions are assigned based on convenience rather than necessity. An agent may only need to read a spreadsheet or respond to support tickets, but it is often granted access to far more powerful systems to avoid friction later. This reduces short-term engineering effort, but it increases long-term operational risk.
The issue is not what the agent is intended to do. The issue is what it is technically allowed to do when behavior deviates from expectations. Once permissions are too broad, there is no structural limit preventing an agent from moving outside its intended scope.
Another common failure point is that permission boundaries are defined once at deployment and then rarely revisited. As agents gain new capabilities and integrations over time, their effective access quietly expands without a deliberate decision to do so.
How to Fix It
The solution is to treat permissions as a core system design constraint, not a prompt-level instruction.
Prompt-based restrictions are not reliable. They can be ignored, bypassed, or misinterpreted. Real control has to exist at the system level, where the agent simply cannot execute actions outside its allowed scope.
Each agent should have explicitly defined access based on the minimum required for its task. If an agent only needs to read data, it should not have write permissions. If it only needs to draft responses, it should not be able to trigger external actions. Equally important, permissions should not remain static. As agents evolve, their access should be reviewed and adjusted with the same discipline used for human role-based access control.
The goal is not to limit capability. The goal is to ensure that capability never exceeds what the task actually requires.
Reason 5: No Observability (Loss of Trust)
One of the less discussed reasons companies roll back AI agents in production is not performance. It’s visibility. When an agent produces an incorrect or unexpected result, the first question from the business is always the same: what actually happened? In many systems, there is no clear answer.
The issue is not that the agent is entirely opaque. It is that most production systems fail to capture the full decision path in a way that is usable. Tool calls, intermediate steps, retrieved context, and external API responses are often partially logged or fragmented across systems.
As a result, when something goes wrong, teams cannot reliably reconstruct the sequence of events. They see the outcome, but not the reasoning path that led to it. At a small scale, this is an engineering inconvenience. At a larger scale, it becomes a trust problem.
When teams cannot explain failures, they stop trusting the system. And when they stop trusting the system, they stop expanding its scope. In many cases, they eventually roll it back entirely, not because it failed consistently, but because it failed in ways they could not understand.
It is one of the key differences between prototypes and production systems. In prototypes, failure is acceptable. In production, unexplained failure is not.
How to Fix It
Production-grade agent systems treat observability as a core requirement, not an add-on. Every decision point needs to be traceable. Every tool call needs to be logged. Every external interaction needs to be recorded in a way that allows the full execution path to be reconstructed.
It includes structured logging, complete tool-call traces, and replay mechanisms that allow teams to step through execution after the fact.
The goal is not just to detect failure, but to make failure explainable. Without that, adoption slows, scope shrinks, and in many cases, the system gets turned off.
What Successful AI Agent Deployments Have in Common
Despite the challenges, organizations are already generating meaningful value from AI agents in production.
The most successful deployments tend to share a few common characteristics.
First, they operate within clearly defined boundaries. Instead of trying to automate entire business functions, they focus on specific responsibilities with a limited set of tools and well-defined objectives.
Second, they are designed to be observable. Teams can see what the agent did, which tools it used, and how it arrived at a decision. When failures occur, they can be investigated and corrected quickly.
Third, they introduce human oversight where mistakes are expensive or difficult to reverse. Low-risk actions can be automated. High-impact actions still require human review.
The common theme is that successful organizations don't treat agents as autonomous employees. They treat them as components within a larger system designed for reliability, accountability, and control.
In many ways, the challenge is similar to onboarding a new team member. You don't start by giving unlimited access to critical systems and expecting perfect judgment. You define responsibilities, establish guardrails, monitor performance, and gradually expand autonomy as trust is earned. The same principle applies to AI agents.
Final Thoughts
The “era of AI agents” has been widely discussed since 2024, yet most organizations remain in pilot or experimental mode. Only a small fraction of teams have moved agents into production at scale. This isn’t because today’s LLMs lack capability. The underlying models are already powerful enough for a wide range of tasks. The real bottleneck is infrastructure maturity. An AI agent is only as reliable as the system built around it. Production success depends on a complete operational stack: robust context management, high-quality retrieval, reliable tool integrations, strict permission boundaries, comprehensive observability, and strong error recovery. The good news? These are solvable engineering problems. The path forward isn’t waiting for smarter models. It’s building better scaffolding around the ones we have today.